Spark 빅데이터 플랫폼 구축에 필요한 사전 개념을 알아보도록 합니다. 데이타 파이프라인을 구축하는 것은 서비스 도메인의 데이타 특성에 대한 이해가 선행되어야 합니다.
프로세스 이해
• Map() : A인 데이터를 B로 변환시키는 계산을 리스트에 대해 수행
List(1,2,3).map(x => x * 2) // result: List(2,4,6)
• Reduce() : 리스트에 들어있는 A, B, C 를 특정 룰에 의해 합치는 작업
List(1,2,3).reduce((a,b) => a + b) // result
• Map() 과 Reduce() 를 조합하면 다양한 작업을 수행할 수 있음
Spark 핵심개념
RDD (Resilient Distributed Dataset – 탄력적으로 분산된 데이터셋)
- 오류 자동복구 기능이 포함된 가상의 리스트
- 다양한 계산을 수행 가능, 메모리를 활용하여 높은 성능을 가짐
Scala Inteface
- 매우 간결한 표현이 가능한 모던 프로그래밍 언어
- Functional Programming이 가능해 데이터의 변환을 효과적으로 표현할 수 있음
그밖의 빅데이터 프로젝트들
• Hadoop을 포함한 Apache 재단 소속 오픈소스 프로젝트들의 영향력이 절대적이지만, Apache 소속이 아닌 프로젝트들도 있음
Presto (Facebook이 리드하는 오픈소스 빅데이터 쿼리엔진)
- HIVE와 유사하지만 압도적인 성능을 가지고 있어 대안으로 인기있음
Elastic Search
- 스케일 가능한 검색, 인덱스 엔진
- 대시보드 도구인 Kibana가 유명하여, 손쉽게 설정하여 사용할 수 있는 ELK 스택이라는 조합도 생겼음 (Elastic Search + Logstash + Kibana)
- 오픈소스 프로젝트이지만 elastic이라는 회사에서 리드하며, 이 회사는 hosted elastic 플랫폼을 서비스함
- 개발자가 kimchy라는 닉네임을 사용하지만 한국사람은 아님
- ES는 아파치 프로젝트는 아니지만 Apache Lucene 기반이며 Apache License로 소스를 제공함
Spark 워크플로우
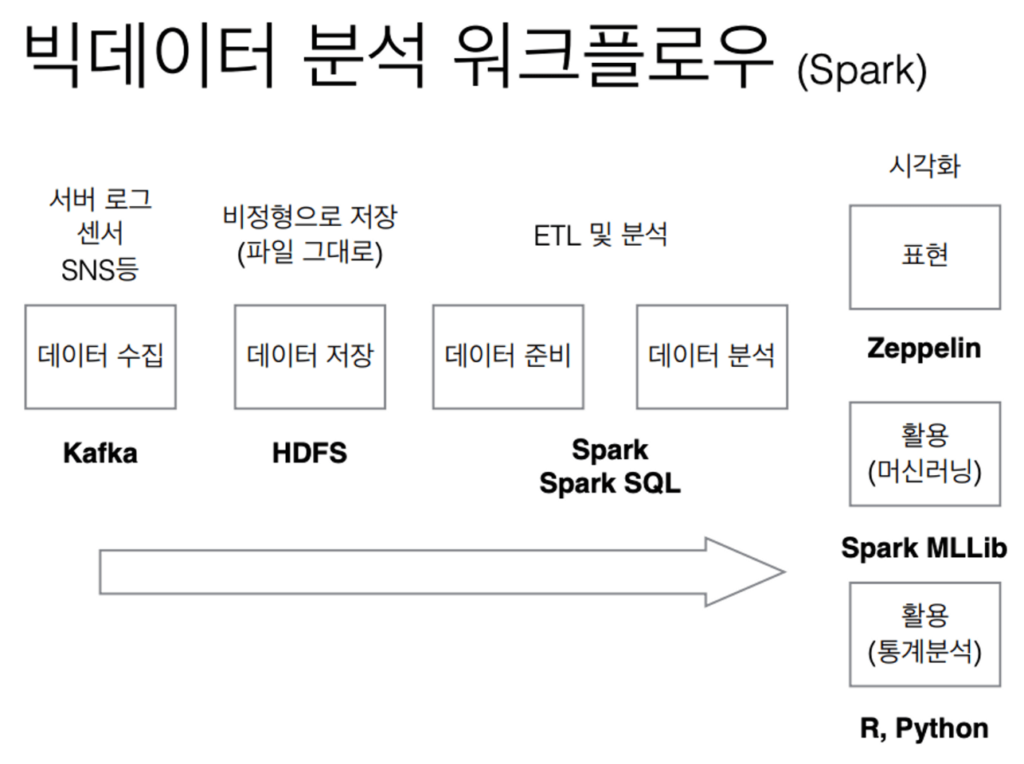
향후 방향성
Apache Spark이 계속 힘을 얻을것
- 강력한 성능과 좋은 인터페이스, 확장성
수많은 사용자와 개발자 • 오픈소스 커뮤니티는 사람들이 원하는대로 발전해 나아감 (민주적)
- 최근 머신러닝에 대한 큰 관심
- 오픈소스 기반 데이터 제품들도 머신러닝 관련 지원이 대폭 강화되는중
- 예: 알고리즘이 대폭 보강된 Spark ML, Tensorflow on Spark 프로젝트
“하둡을 제압한 빅데이터 플랫폼” 아파치 스파크란 무엇인가 – ITWorld Korea
AWS의 데이터 분석 제품들
EMR (Elastic MapReduce)
- https://aws.amazon.com/ko/emr/
- 관리형 하둡 프레임워크: Hive, HBase, Spark 등 다양한 도구들을 바로 사용할 수 있게 설정해줌 (도구들이 설치, 설정된 EC2를 띄워줌)
- EC2 요금 + EMR요금 (EC2요금의 약 5-10%)
Athena
- https://aws.amazon.com/ko/athena/
- Presto기반의 빅데이터 쿼리 서비스
- S3에서 CSV, JSON, Parquet등 데이터 형식을 불러와서 쿼리 가능
Kinesis
- https://aws.amazon.com/ko/kinesis
- Kafka와 유사한 기능을 제공하는 데이터 스트리밍 서비스
- 데이터를 모아서 저장하거나, 모인 데이터를 실시간으로 분석하는 등의 작업 가능
구글클라우드의 데이터 제품들
구글 내부에서 사용하고 있는 도구들을 점점 상용화 하는 식으로 서비스 하고있음
BigQuery
- SQL을 이용하여 수십억 레코드의 데이터를 수초 안에 분석
- 저장 1GB당 월 $0.12 , 처리 1GB당 $0.035
- Web UI, CLI 툴, 여러 언어로 된 API를 제공